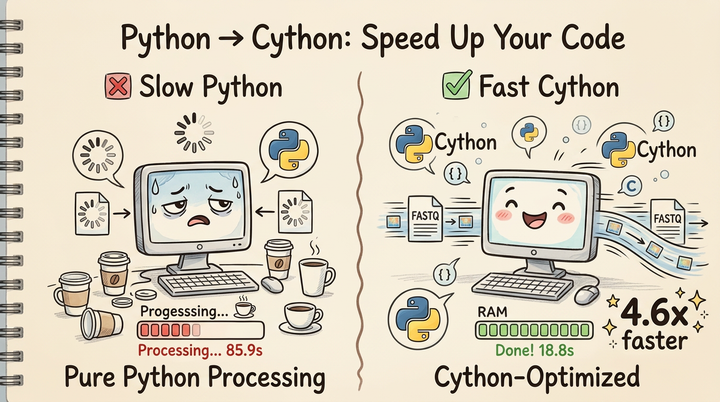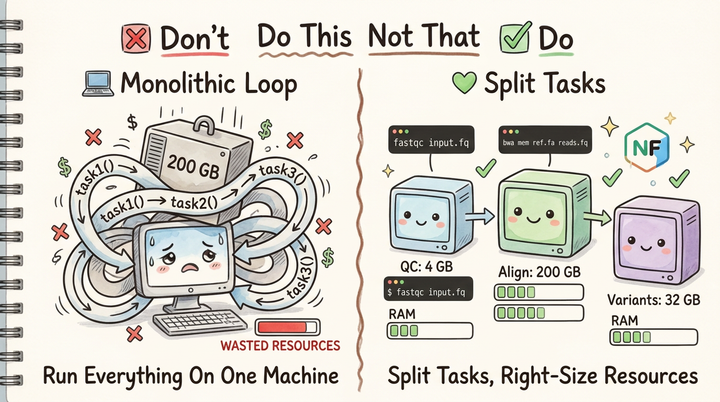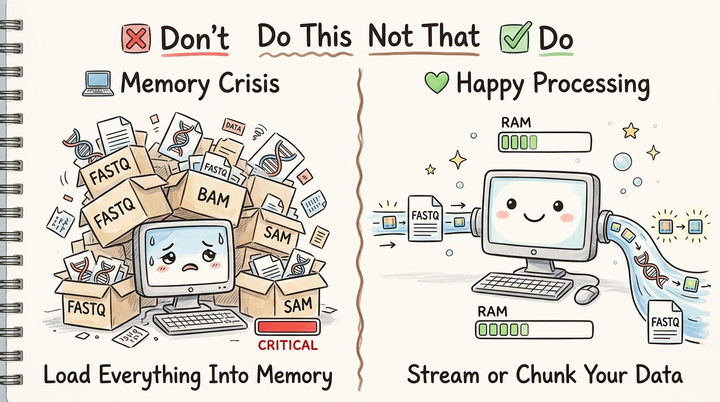
Nextflow Hackathon 2026: Adding QC Reports to nf-core/cellpainting (and Why Data Visualization Matters for AI)
Overview
I just got back from the Nextflow 2026 Hackathon, and it was exactly what my software engineer soul needed. Two days of focused open-source work, surrounded by people who get genuinely excited about workflow orchestration and reproducible pipelines.
More importantly one of the projects was based around cellpainting.