HPC, pipelines & cloud for biotech teams

Build bioinformatics infrastructure your scientists can trust
I’m Jillian Rowe — an independent bioinformatics engineer and infrastructure partner for venture-backed biotech and discovery teams. I help you ship reproducible NGS workflows, credible validation, and AWS / HPC / Kubernetes platforms that scale with your science — without your team becoming full-time DevOps.
Why teams bring me in
Drug discovery moves fast; compute shouldn’t be the bottleneck. I work inside your world — computational chemistry, structural biology, genomics, ML-driven discovery — and bridge the gap between research questions and production-grade systems. That means pipelines people can run with confidence, reporting leadership can use, and infrastructure that passes scrutiny when quality and reproducibility matter.

What I help you deliver
These are the kinds of engagements I take on (often blended on one program):
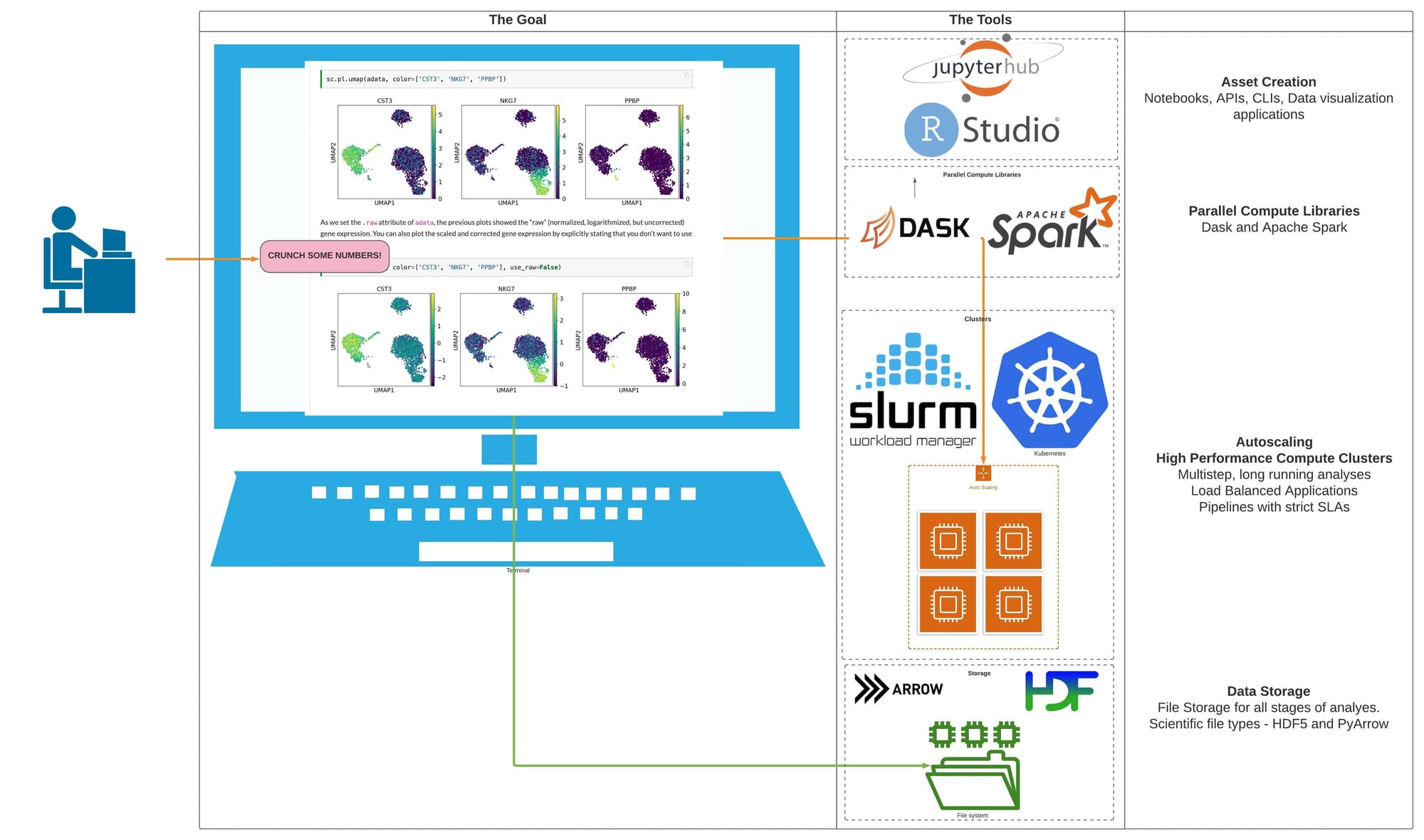
Pipeline verification & quality — Turn “we think it works” into documented, testable primary analysis: from reads through variant calling, with automated checks that fit how your team actually ships code.
Reporting & integration — Connect pipeline outputs to dashboards and decision-makers so computational results don’t sit in a folder — they drive the next experiment or program milestone.
Cloud & DevOps for science — Terraform, CloudFormation, multi-account AWS, CI/CD, and practices that keep scientific computing teams moving without burning down production.
Kubernetes for bioinformatics — Run containerized workflows reproducibly at scale for teams that have outgrown one-off servers.
HPC when you need throughput — ParallelCluster, SLURM, FSx for Lustre, S3 — the elastic “lots of jobs, right-sized cost” story, not a generic IT cluster.
Structure & simulation at scale — ColabFold / AlphaFold-style infrastructure when protein structure is on the critical path.
Reproducible HPC software stacks — EasyBuild, environment modules, and support for the workflows you already run (Nextflow, Snakemake, GROMACS, AMBER, and the rest).
Generative AI that fits the science — AWS Bedrock, Claude, RAG over internal and public data (e.g. OpenTargets) when teams need answers from literature and proprietary data, not another generic chatbot.
Who this is for
I’ve partnered with venture-backed biotech and specialized shops across computational chemistry, genomics, and ML-driven discovery — supporting dozens of scientists on production systems. Names you may recognize include Moma Therapeutics, Terremoto Biosciences, Septerna, Cytomx, Cellarity, and others — plus bioinformatics CRO work. If you’re scaling discovery and need someone who speaks both science and AWS, we should talk.
Let’s talk about your next build
Tell me what you’re trying to validate, deploy, or scale — send a note and we’ll see if there’s a fit.