
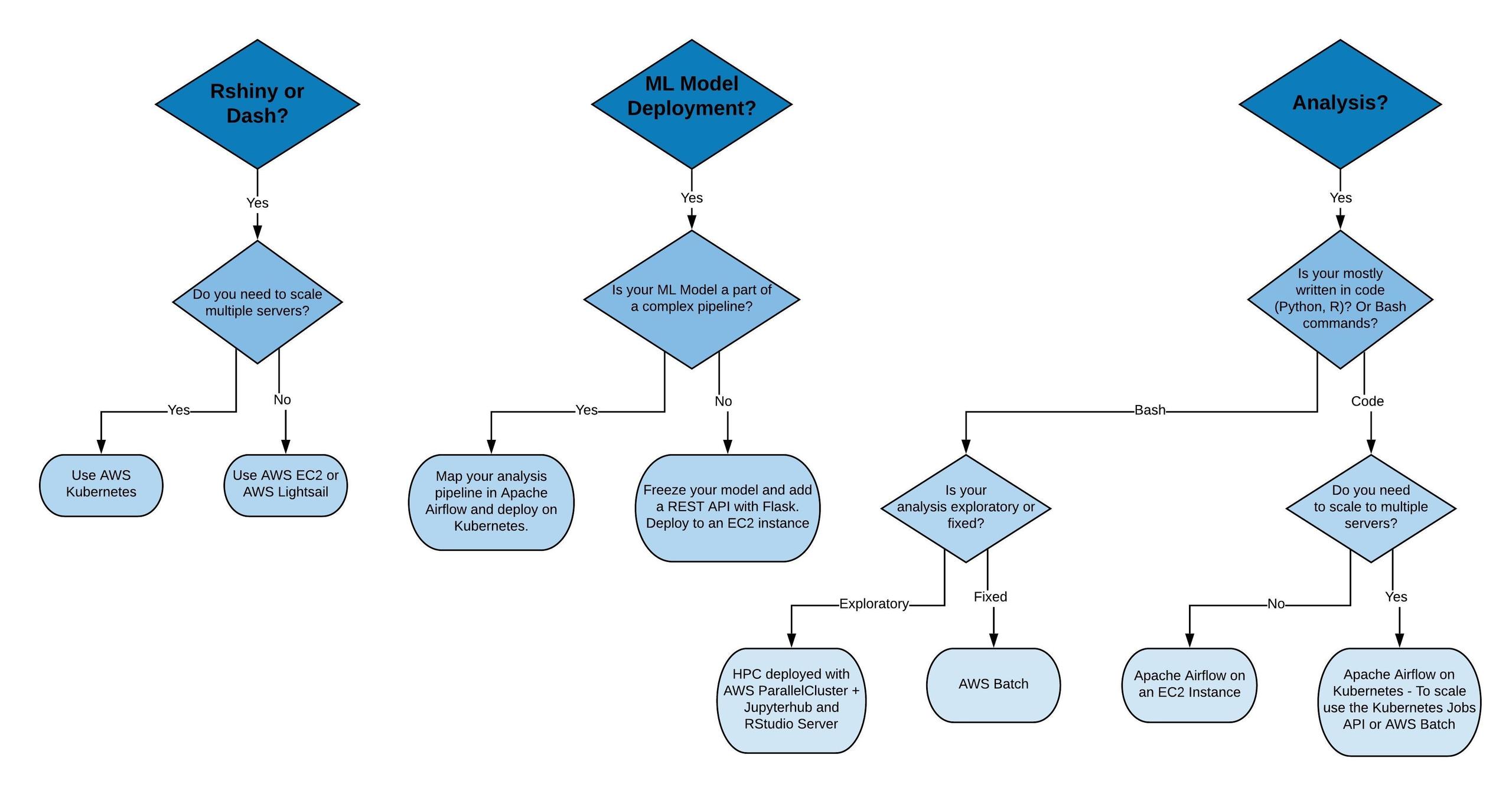
Do you have a WGS, exome, single-cell, HCS or imaging dataset that is too large to analyze using your standard approaches?
Is your team babysitting analyses because you don’t have an automated and optimized system for submitting datasets to a compute cluster?
Do all the compute options on AWS (Docker, Batch, SLURM, ECS, Swarm, Kubernetes) have your head spinning?
Do you want to scale and automate crunching numbers so you can focus on the science?
Imagine knowing which compute option is right for your analysis without having to wade through all the options.
Instead of spending countless hours researching different compute infrastructures have a ready to execute the plan for rolling out and scaling your compute infrastructure.
We’ll hop on a call for 1 hour to discuss:
- Your analysis types and components. (Do you need to preprocess images before running Cellprofiler? Or filter variants before analyzing your population statistics?)
- What types of datasets you have
- Existing compute infrastructure (if any)
- Whether your analysis is more exploratory or set
- Additional helpful tools you need, custom RStudio Server implementations, data sharing, on demand compute clusters for web applications, etc.
Once we've discussed your datasets and analysis goals I will recommend 1 or more compute options on AWS. After our call, you will receive a report that tells you in detail which option is right for you and why along with a plan to implement your shiny new compute infrastructure!
AWS Compute Infrastructure Strategy Session

Book Your Call
You'll book your call through our calendar. From there, if you like, you can send an overview of your computational challenges and goals.

Analyze Your Needs
Once on the call we'll go over your most pressing concerns and decide on the best course of action for your dataset and analysis type.

Report
After our call you will receive a full report with my recommended compute infrastructure or analysis optimizations.
Why Work With Me?
Over the course of my career, I have earned a robust reputation for outstanding genomics and bioinformatics DevOps, and I am known for my ability to design and integrate innovative, flexible infrastructures, leveraging in-depth client and business consultation to uncover critical, unique program needs. Throughout the years I’ve seen datasets grow in size and complexity (who remembers microarrays?) and worked with researchers to develop analysis infrastructure to accommodate the ever-growing demand for more number crunching.
I have consulted with the Bioinformatics Contract Research Organization (CRO) and BitBio to design and deploy a major manual-labor saving HPC cluster with integrated SLURM scheduler and user / software stacks, and elastic computational infrastructure for genomics analysis, empowering a greater focus on high-priority projects and activities.
I also designed and deployed complex data visualization applications on AWS such as NASQAR. I am both a contributor and core team member of Bioconda as well as a contributor to the Conda Ecosystem and EasyBuild.

Ready to get started?
Click here to get started, and then you'll be taken to a scheduling page.
Book Now
I schedule calls on a first-come, first-serve basis, with priority given to my current clients. Book now to make sure your project is analyzed.